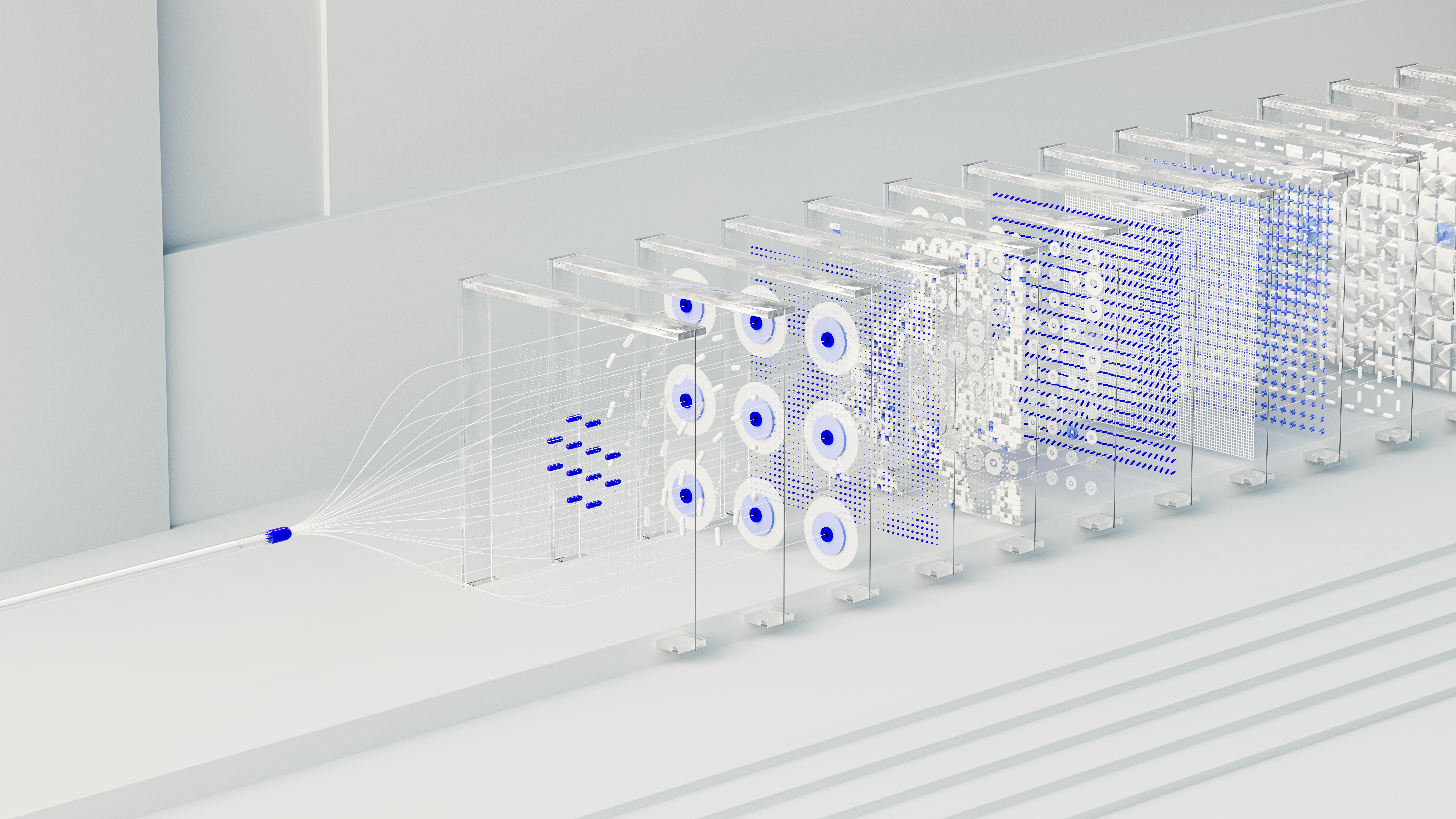
QARI is not static. It improves over time through a three-stage learning system. Each stage activates when a specific data milestone is reached. At launch, the platform runs Stage 1. As more trades are completed across the platform, it progresses to Stage 2 and then Stage 3. Every closed trade contributes to this collective improvement, without ever exposing individual user data.
Stage 1: Rule-Based Static Weights
In Stage 1, the 11 layers are weighted using fixed values calibrated from historical backtesting and the operator's expert knowledge of market structure. These weights do not change automatically. They represent the best-known configuration before platform-generated trade data is available.
Stage 1 properties
- Fully deterministic: the same market conditions will always produce the same score.
- No learning from outcomes: weights do not shift based on whether trades win or lose.
- Calibrated from historical data: weights were set during the Phase 2G calibration backtest.
- Active from day one: no data accumulation required.
- Solid foundation: conservative weights that prioritise setup quality over frequency.
Stage 2: Adaptive Weights (After 500 Trades)
After 500 completed trades are recorded across the platform, Stage 2 activates. At this point, QARI has enough outcome data to statistically evaluate which layer combinations are most predictive of winning trades.
Stage 2 uses a statistical weight tuner that periodically re-calculates the contribution weight of each layer based on trade outcomes. If L2 (SFP) has been highly predictive of winning trades in the current market regime, its weight increases. If L8 (order book) has been less predictive, its weight decreases.
Collective model
The platform-wide model uses all anonymised trade data. Weights adapt to collective patterns observed across all users.
Premium personalised model
Premium subscribers also get a secondary model that weights their own trade history. If your personal setup preferences show different patterns, the personalised model learns them.
How anonymisation works
Before any trade outcome is recorded for training, all identifying information is stripped. User ID, exchange, pair, timestamps, and prices are removed. Only the feature vector (the 11-layer scores) and the outcome (win/loss/R-multiple) are stored.
Drift detection
If the adapted weights cause accuracy to fall below 15% below the Stage 1 baseline on a rolling window, Stage 2 automatically reverts to Stage 1 weights as a safety fallback.
Stage 3: LightGBM Machine Learning (After 2,000 Trades)
After 2,000 completed trades, QARI activates the LightGBM model. LightGBM is a gradient boosting framework that can learn non-linear relationships between features. Stage 2's linear weight adjustment cannot capture complex interactions between layers. Stage 3 can.
For example: Stage 2 might learn that L6 (Fibonacci) is generally predictive. Stage 3 can learn that L6 is highly predictive specifically when combined with L2 (SFP) and L9 (VWAP) in a TRENDING regime, but much less so in a RANGING regime.
Stage 3 milestones
The Stage 1 rule-based model always runs in parallel as a fallback. If the ML model's confidence falls below acceptable thresholds, Stage 1 provides the final decision gate.
What Data Is Used
The training data contains only two types of records for each trade: the feature vector (the 11-layer scores and sub-scores at the time of entry) and the outcome label (win, loss, partial win, and the R-multiple achieved).
What IS in the training data
- All 11 layer scores (anonymous numbers)
- Market regime at entry (TRENDING, RANGING, VOLATILE)
- Session context at entry (Asian, London, NY)
- Outcome: win/loss/partial and R-multiple
What is NOT in the training data
- User ID or any user identifier
- Exchange or account details
- Specific trading pair or price levels
- Timestamps
- Position size or USDT amounts
How Your Trades Make QARI Better
Every trade you complete adds one anonymised record to the collective training dataset. When your trade closes, the feature vector that generated the entry is stored alongside the outcome. This happens automatically if you have consented to collective intelligence contribution (asked during registration).
The more trades across the platform, the more accurately QARI can identify which combinations of layers genuinely predict outcomes versus those that produce false positives in specific market conditions.
Opt-out: You can disable collective intelligence contribution at any time from the Settings page without affecting your trading. If you opt out, your trade outcomes are not included in the shared training data. QARI will still learn from platform-wide data, but your own trades will not contribute.
Contribution is the default because it benefits all users collectively. A platform with 100 traders sharing outcomes learns 100x faster than one user's isolated history. Everyone's QARI performs better as the platform grows.